


 tự hành, nhà quản lý phải đối mặt với một thách thức mới: Làm sao để kiểm soát hệ thống thay vì bị hệ thống kiểm soát? Bạn đã sẵn sàng để nâng cấp vai trò từ người thực thi tác vụ sang nhà chiến lược AI?")
Retrieval-Augmented Generation (RAG) là gì?
Last updated: March 22, 2026 Xem trên toàn màn hình
- 14 Aug 2025
 Văn bản do AI tạo ra có cấu trúc khác với văn bản con người tạo ra như thế nào? 148/211
Văn bản do AI tạo ra có cấu trúc khác với văn bản con người tạo ra như thế nào? 148/211 - 04 Dec 2025 [Giải mã AI] "Text burstiness" và "text perplexity" là gì? 125/185
- 23 Aug 2024 Nghịch lý toán học chứng minh giới hạn của AI 114/436
- 27 Mar 2026 10 khái niệm AI quan trọng mà mọi kỹ sư công nghệ cần nắm vững 110/133
- 24 Mar 2026 Năm nghề nghiệp mới có thể xuất hiện trong tương lai AI 102/129
- 27 Jun 2025 Avatar AI trong Metaverse: Cách Những Thực Thể Số Đang Tái Định Nghĩa Bản Sắc và Tương Tác Xã Hội 99/335
- 19 Jun 2024 Giải mã AI, ML và DL: Chìa khóa nắm bắt xu hướng chuyển đổi số 99/302
- 27 Nov 2024 Ứng dụng AI theo dõi thu chi gây sốt vì 'mắng' người tiêu tiền 98/251
- 19 Jan 2025 AI Agents: Ngọn Hải Đăng Dẫn Lối Khởi Nghiệp Trong Kỷ Nguyên Số 86/271
- 02 Jul 2025 Doanh nghiệp đối diện CHI PHÍ ẨN khi không áp dụng "AI Agents": Lộ diện nguy cơ tụt hậu 81/165
- 03 May 2024 AI Đàm Thoại (Conversational AI) – Cuộc Cách Mạng Công Nghệ Đầy Hứa Hẹn 81/261
- 01 Sep 2025 AI đang thay đổi khoa học quản trị hiện đại như thế nào 78/138
- 11 Dec 2025 12 lợi ích của tự động hóa quy trình làm việc 75/92
- 01 Mar 2024 Google thử nghiệm Search AI (Search Generative Experience - SGE) 72/460
- 23 Apr 2025 Multimodal Agent AI – Cuộc cách mạng trong tương tác người – máy 69/221
- 11 Dec 2025 Claude Code là gì? 69/80
- 28 Nov 2025 AI có thể chống lại “tư duy bầy đàn” trong doanh nghiệp? 67/110
- 20 Mar 2026 [Việc Làm] Tuyển dụng AI Engineer 64/94
Bối cảnh ra đời
Không chỉ các mô hình nền tảng (foundation models) bị “mắc kẹt trong quá khứ”, mà chúng còn cố ý tạo ra các phản hồi nghe tự nhiên và đa dạng. Cả hai điều này có thể dẫn đến đầu ra sai lệch hoặc không liên quan nhưng lại rất tự tin. Hành vi này được gọi là “hallucination” (ảo giác).
Trong bài viết này, chúng ta sẽ khám phá những hạn chế của foundation models và cách retrieval-augmented generation (RAG) có thể giải quyết các hạn chế đó, giúp các hệ thống chat, search và agentic workflows hoạt động hiệu quả hơn.
Hạn chế của foundation models
Các sản phẩm xây dựng chỉ dựa trên foundation models tuy rất mạnh mẽ nhưng vẫn tồn tại nhiều điểm yếu:
Giới hạn kiến thức (Knowledge cutoffs)
Khi bạn hỏi các model hiện tại về các sự kiện gần đây – ví dụ như trận bóng rổ NBA tuần trước hay cách sử dụng tính năng mới của iPhone – chúng có thể trả lời một cách tự tin nhưng thông tin lại lỗi thời hoặc hoàn toàn bịa đặt (hallucination).
Các model được huấn luyện trên lượng dữ liệu khổng lồ (code, sách, website, hội thoại, paper khoa học…). Tuy nhiên, sau khi huấn luyện xong, dữ liệu bị “đóng băng” tại một thời điểm gọi là cutoff. Điều này tạo ra khoảng trống kiến thức (knowledge gap), khiến model tạo ra câu trả lời nghe hợp lý nhưng sai.
Thiếu chiều sâu chuyên ngành (Lack depth in domain-specific knowledge)
Foundation models có kiến thức rộng nhưng thiếu chiều sâu ở các lĩnh vực chuyên biệt.
Ví dụ: một model y học có thể hiểu về giải phẫu, bệnh lý, phẫu thuật, nhưng gặp khó với bệnh hiếm hoặc liệu pháp mới. Dữ liệu có thể tồn tại nhưng không đủ để huấn luyện hiệu quả, hoặc cần chuyên gia để gắn ngữ cảnh.
Kết quả: câu trả lời có thể thiếu sót hoặc không liên quan.
Thiếu dữ liệu nội bộ hoặc sở hữu độc quyền (Lack private or proprietary data)
Các model public không có quyền truy cập vào dữ liệu riêng của bạn như:
- quy trình nội bộ
- dữ liệu nhân sự
- bí mật kinh doanh
Điều này là cần thiết để bảo mật, nhưng cũng khiến model không hiểu business của bạn, dẫn đến câu trả lời kém hữu ích.
Mất niềm tin (Loses trust)
Model thường không trích dẫn nguồn. Người dùng phải:
- hoặc tin vào câu trả lời
- hoặc tự kiểm chứng
Vì dữ liệu huấn luyện đến từ nhiều nguồn, có thể bao gồm nguồn không đáng tin, nên khi model sai → người dùng mất niềm tin.
Tạo đầu ra theo xác suất (Output generation is probabilistic)
Model hoạt động theo xác suất:
- dữ liệu huấn luyện có thể chứa lỗi, mâu thuẫn
- model gán xác suất cho nhiều khả năng, kể cả sai
Cộng với yếu tố như:
- temperature
- top-k sampling
- prompt mơ hồ
→ model có thể chọn đáp án sai → sinh hallucination.
Ngoài ra, model không phân biệt rõ:
- cái nó biết
- cái nó không biết
→ vẫn trả lời rất tự tin dù sai.
Điều này có thể nguy hiểm, ví dụ:
- báo cáo y khoa sai → dẫn đến điều trị sai hoặc không điều trị
👉🏻 Những hạn chế này ảnh hưởng trực tiếp đến:
- hiệu quả kinh doanh
- niềm tin người dùng
→ Đây là lý do RAG ra đời.
Retrieval-Augmented Generation (RAG) là gì?
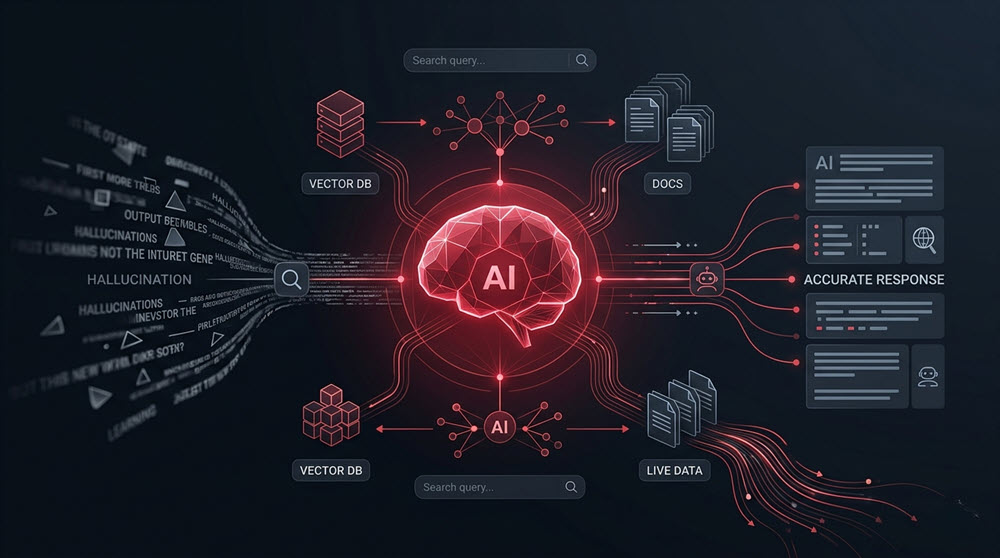
Retrieval-Augmented Generation (RAG) là một phương pháp kết hợp giữa truy xuất thông tin (retrieval) và tạo sinh nội dung (generation) trong các hệ thống AI. Thay vì chỉ dựa vào kiến thức đã được học sẵn trong foundation models, RAG cho phép mô hình “tra cứu” thêm dữ liệu từ các nguồn bên ngoài (như cơ sở dữ liệu, tài liệu nội bộ, hoặc internet) ngay tại thời điểm người dùng đặt câu hỏi.
RAG là kỹ thuật sử dụng dữ liệu bên ngoài (authoritative, external data) để cải thiện:
- độ chính xác (accuracy)
- tính liên quan (relevance)
- tính hữu ích (usefulness)
Nhờ đó, mô hình không chỉ trả lời dựa trên trí nhớ tĩnh, mà còn dựa trên ngữ cảnh thực tế, cập nhật và phù hợp hơn, giúp cải thiện đáng kể độ chính xác, tính liên quan và độ tin cậy của câu trả lời.
- Ingestion
Dữ liệu (ví dụ: dữ liệu nội bộ) được đưa vào nguồn dữ liệu như vector database (Pinecone) - Retrieval
Truy xuất dữ liệu liên quan dựa trên câu hỏi người dùng - Augmentation
Kết hợp dữ liệu truy xuất + câu hỏi → tạo prompt có ngữ cảnh - Generation
Model tạo câu trả lời dựa trên prompt đã được augment
Lợi ích của RAG
- Truy cập dữ liệu real-time & proprietary (thời gian thực và độc quyền nội bộ)
- Tăng độ tin cậy (có thể trích nguồn)
- Kiểm soát tốt hơn
- Tiết kiệm chi phí hơn so với:
- train model mới
- fine-tuning (tinh chỉnh)
- đặt vào context rộng lớn hơn
RAG trong agentic workflows
RAG truyền thống khá đơn giản (1 query → 1 lần truy xuất → trả lời).
Với sự xuất hiện của AI agents, RAG trở nên mạnh hơn:
Agent có thể:
- viết lại query tốt hơn
- chọn tool truy xuất
- đánh giá độ liên quan
- suy luận và kiểm chứng thông tin
→ tạo ra hệ thống thông minh hơn, có khả năng lặp (iterative) và ra quyết định tốt hơn.
RAG hoạt động như thế nào?
1. Ingestion
- Chunk dữ liệu: Chia tài liệu thành các đoạn nhỏ (chunk)
- Tạo vector embeddings: Dùng embedding model để chuyển chunk → vector (biểu diễn số học)
-
Lưu vào vector database: Ví dụ Pinecone
2. Retrieval
- Dùng semantic search (hiểu nghĩa)
- Kết hợp lexical search (keyword)
→ gọi là hybrid search
Sau đó:
- gộp kết quả
- loại trùng
- rerank theo độ liên quan
3. Augmentation
Tạo prompt dạng:
QUESTION:
<câu hỏi>
CONTEXT:
<dữ liệu truy xuất>
Hãy trả lời dựa trên CONTEXT. Nếu không có thông tin, hãy nói không biết.4. Generation
LLM sử dụng context để:
- trả lời chính xác hơn
- giảm ảo giác (hallucination)
Agentic RAG là gì?
Không chỉ là “tìm thông tin rồi trả lời”, mà là:
- chọn câu hỏi nào cần hỏi
- chọn tool nào cần dùng
- quyết định khi nào dùng
- tổng hợp kết quả
→ RAG + agent = hệ thống lập luận (reasoning) mạnh mẽ hơn
Tổng kết
RAG đã tiến hóa từ một từ khóa (buzzword) trở thành nền tảng cốt lõi của AI hiện đại
RAG kết hợp:
- sức mạnh của foundation models
- dữ liệu riêng của doanh nghiệp
Trong tương lai:
- AI agents sẽ ngày càng tự động hơn
- workflow ngày càng phức tạp hơn
→ RAG trở thành bắt buộc, không còn là “có nên dùng hay không”
→ mà là: thiết kế RAG như thế nào cho hiệu quả nhất
 dự án. Khi phần vượt lớn hơn phần phải có (trong phạm vi) thì dẫn đến một loạt các sụp đổ (công việc, chất lượng, tiến độ...)")
 trở nên cuốn hút và chạm đến cảm xúc người xem?")























 Link copied!
Link copied!
 Mới cập nhật
Mới cập nhật