 là gì, vì sao nhiều chuyên gia tin rằng AI có thể vượt khỏi tầm kiểm soát của con người?")



VGG Image Annotator là gì?
Published on: January 16, 2025
Last updated: March 18, 2025 Xem trên toàn màn hình
Last updated: March 18, 2025 Xem trên toàn màn hình
- 14 Aug 2025
 Văn bản do AI tạo ra có cấu trúc khác với văn bản con người tạo ra như thế nào? 233/303
Văn bản do AI tạo ra có cấu trúc khác với văn bản con người tạo ra như thế nào? 233/303 - 12 Nov 2024 Retrieval-Augmented Generation (RAG) là gì? 193/253
- 19 Jun 2024 Giải mã AI, ML và DL: Chìa khóa nắm bắt xu hướng chuyển đổi số 157/380
- 14 Jan 2024 Airtable là ứng dụng gì? 139/462
- 23 Aug 2024 Nghịch lý toán học chứng minh giới hạn của AI 135/470
- 09 Oct 2025 Giải đáp bộ 3 công cụ monitoring/logging stack: ELK, Grafana và Prometheus 125/199
- 27 Nov 2024 Ứng dụng AI theo dõi thu chi gây sốt vì 'mắng' người tiêu tiền 122/280
- 02 Jul 2025 Doanh nghiệp đối diện CHI PHÍ ẨN khi không áp dụng "AI Agents": Lộ diện nguy cơ tụt hậu 120/205
- 28 Nov 2025 AI có thể chống lại “tư duy bầy đàn” trong doanh nghiệp? 119/165
- 01 Sep 2025 AI đang thay đổi khoa học quản trị hiện đại như thế nào 117/178
- 19 Jan 2025 AI Agents: Ngọn Hải Đăng Dẫn Lối Khởi Nghiệp Trong Kỷ Nguyên Số 110/300
- 27 Dec 2024 Chuyển hình ảnh thành văn bản có thể chỉnh sửa cực nhanh – Khám phá ngay! 110/321
- 03 May 2024 AI Đàm Thoại (Conversational AI) – Cuộc Cách Mạng Công Nghệ Đầy Hứa Hẹn 101/282
- 11 Dec 2025 Claude Code là gì? 99/114
- 03 Oct 2021 Elsa Speak: Công nghệ sẽ khai phóng tiềm năng ngôn ngữ nhờ tích hợp AI 97/745
- 28 Aug 2024 K-INNOVATION: SỰ KIỆN XÚC TIẾN THƯƠNG MẠI VIỆT NAM - HÀN QUỐC 96/485
- 23 Apr 2025 Multimodal Agent AI – Cuộc cách mạng trong tương tác người – máy 93/251
- 01 Mar 2024 Google thử nghiệm Search AI (Search Generative Experience - SGE) 90/480
- 05 Feb 2025 Kỹ thuật 'Chưng Cất' là gì khiến các công ty AI tiên phong lo ngại? 72/143
- 06 Mar 2023 KISA - Mô hình đánh giá an toàn thông tin của Hàn Quốc 65/259
- 21 Jul 2026 Phân biệt Machine Learning (ML) và Deep Learning (DL) Frameworks 35/41
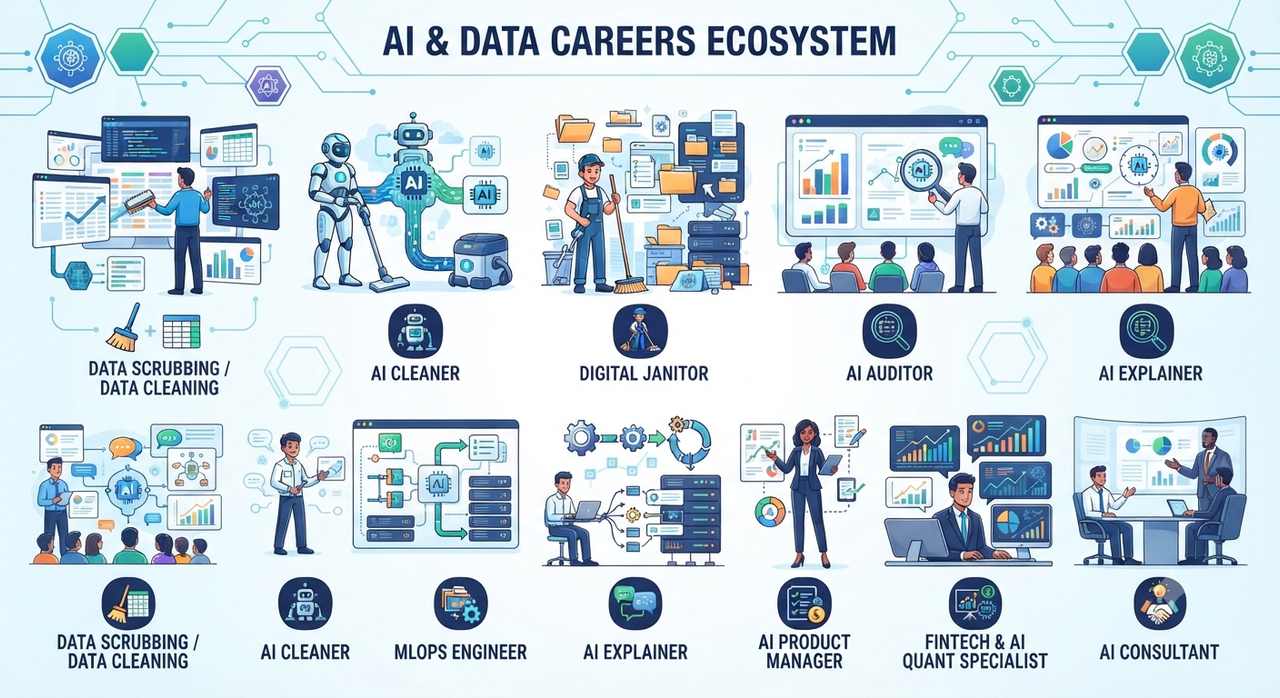
VGG Image Annotator (VIA) là gì?
VGG Image Annotator (VIA) là một công cụ gán nhãn ảnh mã nguồn mở, nhẹ và dễ sử dụng do nhóm VGG tại Đại học Oxford phát triển. VIA hỗ trợ nhiều loại định dạng gán nhãn như bounding box, polygon, point, và region attributes, giúp người dùng tạo dữ liệu huấn luyện cho các mô hình thị giác máy tính (computer vision). VIA hoạt động hoàn toàn trên trình duyệt, không yêu cầu cài đặt server hay kết nối internet.
Giới hạn "vùng xám" (grey area) của VGG Image Annotator
Mặc dù VIA có ưu điểm là miễn phí và đơn giản, nhưng nó vẫn có một số giới hạn, bao gồm:
Không có tự động hóa gán nhãn
- VIA không sử dụng AI để hỗ trợ gán nhãn, vì vậy toàn bộ quá trình phải được thực hiện thủ công, dẫn đến mất nhiều thời gian khi làm việc với lượng lớn dữ liệu.
Không hỗ trợ cộng tác trực tiếp
- VIA không có tính năng cộng tác theo thời gian thực, khiến việc chia sẻ dữ liệu và phối hợp giữa nhiều annotator trở nên khó khăn.
Quản lý dữ liệu thủ công
- Người dùng phải tự tổ chức và lưu trữ dữ liệu, thay vì có một hệ thống quản lý tập trung như các dịch vụ cloud. Điều này có thể dẫn đến sai sót hoặc mất mát dữ liệu.
Không tích hợp trực tiếp với hệ thống cloud hoặc ML pipeline
- VIA không có tích hợp sẵn với AWS, Google Cloud, hay các nền tảng machine learning khác, nên việc sử dụng trong quy trình huấn luyện mô hình AI đòi hỏi các bước xử lý thủ công.
Hạn chế về khả năng mở rộng
- Khi làm việc với tập dữ liệu lớn, VIA có thể gặp giới hạn về hiệu suất do phải tải toàn bộ dữ liệu vào trình duyệt.
So sánh VIA với Amazon SageMaker Ground Truth
| Tiêu chí | VGG Image Annotator (VIA) | Amazon SageMaker Ground Truth |
|---|---|---|
| Chi phí | Miễn phí (mã nguồn mở) | Tính phí theo mức sử dụng |
| Gán nhãn tự động | Không có | Có, sử dụng AI để hỗ trợ |
| Cộng tác nhóm | Không hỗ trợ trực tiếp | Có hỗ trợ trên nền tảng AWS |
| Tích hợp cloud & ML pipeline | Không có | Tích hợp chặt chẽ với AWS |
| Hiệu suất với tập dữ liệu lớn | Hạn chế do hoạt động trên trình duyệt | Tối ưu cho quy mô lớn |
| Độ phức tạp khi sử dụng | Dễ sử dụng, không yêu cầu cài đặt | Cần thiết lập trên AWS |
| Bảo mật dữ liệu | Do người dùng tự quản lý | AWS có cơ chế bảo mật tốt hơn |
Kết luận
- VIA phù hợp cho những ai muốn gán nhãn ảnh nhanh chóng, đơn giản và không cần tự động hóa. Nó lý tưởng cho các dự án nhỏ hoặc cá nhân.
- SageMaker Ground Truth mạnh mẽ hơn, phù hợp với doanh nghiệp cần gán nhãn dữ liệu quy mô lớn, có hỗ trợ AI để tăng tốc độ và giảm chi phí.
Nếu bạn cần một giải pháp nhanh, miễn phí và không phụ thuộc vào cloud, VIA là lựa chọn tốt. Nhưng nếu bạn cần một hệ thống mạnh mẽ, có tự động hóa và quản lý dữ liệu tốt, SageMaker Ground Truth sẽ phù hợp hơn.
[{"displaySettingInfo":"[{\"isFullLayout\":false,\"layoutWidthRatio\":\"\",\"showBlogMetadata\":true,\"showAds\":true,\"showQuickNoticeBar\":true,\"includeSuggestedAndRelatedBlogs\":true,\"enableLazyLoad\":true,\"quoteStyle\":\"1\",\"bigHeadingFontStyle\":\"1\",\"postPictureFrameStyle\":\"1\",\"isFaqLayout\":false,\"isIncludedCaption\":false,\"faqLayoutTheme\":\"1\",\"isSliderLayout\":false}]"},{"articleSourceInfo":"[{\"sourceName\":\"\",\"sourceValue\":\"\"}]"},{"privacyInfo":"[{\"isOutsideVietnam\":false}]"},{"tocInfo":"[{\"isEnabledTOC\":true,\"isAutoNumbering\":false,\"isShowKeyHeadingWithIcon\":false}]"},{"termSettingInfo":"[{\"showTermsOnPage\":false,\"displaySequentialTermNumber\":false}]"}]
Nguồn
{content}



 tiến hành với 182 giám đốc điều hành từ các ngành khác nhau, chỉ có 17% cho biết rằng các cuộc họp tại công ty mình nói chung là có hiệu quả; trong khi 65% khẳng định, họp làm ảnh hưởng tới công việc cá nhân!")








.")

 với giải thích chi tiết Anh – Việt, giúp bạn làm chủ cảm xúc, nâng cao EQ và tìm thấy sự bình an giữa thời đại AI và VUCA.")











 Link copied!
Link copied!
 Mới cập nhật
Mới cập nhật
 thực chiến - Kiến tạo tương lai cho các nhà sáng tạo nội dung.
thực chiến - Kiến tạo tương lai cho các nhà sáng tạo nội dung.